Code
qnorm(0.83) # the value of "Z" where its cumulative probability under a standard normal distribution is 0.83[1] 0.9541653Code
qnorm(0.975) # similarly, the value of "Z" where the CDF indicates 0.975 area under the curve[1] 1.959964This page is part of the University of Colorado-Anschutz Medical Campus’ BIOS 6618 Recitation collection. To view other questions, you can view the BIOS 6618 Recitation collection page or use the search bar to look for keywords.
Power and type I error rates are some of the more challenging aspects of statistics. They naturally have strange interpretations and don’t always follow a natural way of thinking. In this recitation we will focus heavily on these concepts as they relate to the homework and statistics more generally.
| Reality → What we decide ↓ |
\(H_0\) True | \(H_0\) False/\(H_1\) True |
|---|---|---|
Fail to reject \(H_0\) |
Correct Probability of correct decision = \(1-\alpha\) = level of confidence |
Type II Error P(Type II Error)=\(\beta\) |
Reject \(H_0\) |
Type I Error P(Type I Error) = \(\alpha\) (level of significance) |
Correct Probability of correct decision = \(1-\beta\) = Power |
Our 2x2 table summarizes the unknown reality of our hypothesis test and the conclusions we make based on a sample we collect to run the hypothesis test on. We see that there are four possible outcomes, two of which are correct and two of which represent erroneous conclusions. It is these erroneous conclusions that lead to Type I and Type II Errors, which are the probability of a false positive or false negative, respectively.
When we make the assumption that the standard deviation is known or unknown for a power calculation, we end up two different conclusions as to the possible power, needed sample size, the difference we can detect, etc. This is because the assumption of known standard deviation allows us to use the normal distribution for our power calculation, whereas the unknown standard deviation implies we have to estimate the SD from our sample and we end up using the t-distribution.
The reason for the distributional change is that we need to account for the additional uncertainty introduced by estimating the SD. If we treat the SD as known then it is a constant value (i.e., whatever we “know” it to be). If the SD is unknown, we know the sampling distribution is \(\chi^2_{n-1}\) (where \(n-1\) is our degrees of freedom).
A new treatment for celiac disease, an autoimmune condition where people cannot eat wheat, barley, or rye due to the body perceiving it as an immune threat, has been developed. Previously the only “treatment” for celiac disease was a strict adherence to a gluten-free diet, but a researcher believes the new treatment will allow individuals to eat foods that may have been cross-contaminated with gluten without activating their immune system and destroying their small intestine.
One way to measure the effectiveness of the treatment is examine the change in the level of antibodies in a participant’s blood after exposure to cross-contaminated meals. One such antibody test is the Tissue Transglutaminase IgA antibody (tTG-IgA) test. The researcher desires 83% power to detect a change of 5 U/mL (units per milliliter) with \(\alpha=0.05\) and \(\sigma=5\).
Let’s first calculate the known SD case: \[ n = \frac{\sigma^2 \left( Z_{1-\beta} + Z_{1-\frac{\alpha}{2}} \right)^2}{(\mu_0 - \mu_1)^2} \]
We know from our problem that we need to calculate \(Z_{1-\beta} = Z_{0.83}\) and \(Z_{1-\frac{\alpha}{2}} = Z_{0.975}\). We can do this in R with the qnorm function:
qnorm(0.83) # the value of "Z" where its cumulative probability under a standard normal distribution is 0.83[1] 0.9541653qnorm(0.975) # similarly, the value of "Z" where the CDF indicates 0.975 area under the curve[1] 1.959964\(\begin{aligned} n =& \; \frac{\sigma^2 \left( Z_{1-\beta} + Z_{1-\frac{\alpha}{2}} \right)^2}{(\mu_0 - \mu_1)^2} \\ =& \; \frac{5^2(Z_{0.83} + Z_{0.975})^2}{5^2} \\ =& \; \frac{5^2 (0.95 + 1.96)^2}{25} \\ =& \; 8.4681 \end{aligned}\)
When the SD is known we would need to enroll 9 participants (remember we need to round up, especially if our investigator wants at least 83% power).
Let’s graphically compare our distribution of the null and alternative distribution for \(\bar{X}\) under the known SD assumption first. Recall, \(\bar{X} \sim N(\mu,\frac{\sigma^2}{n})\), so for our sample size calculation we have \(\bar{X} \sim N(\mu,\frac{25}{9})\).
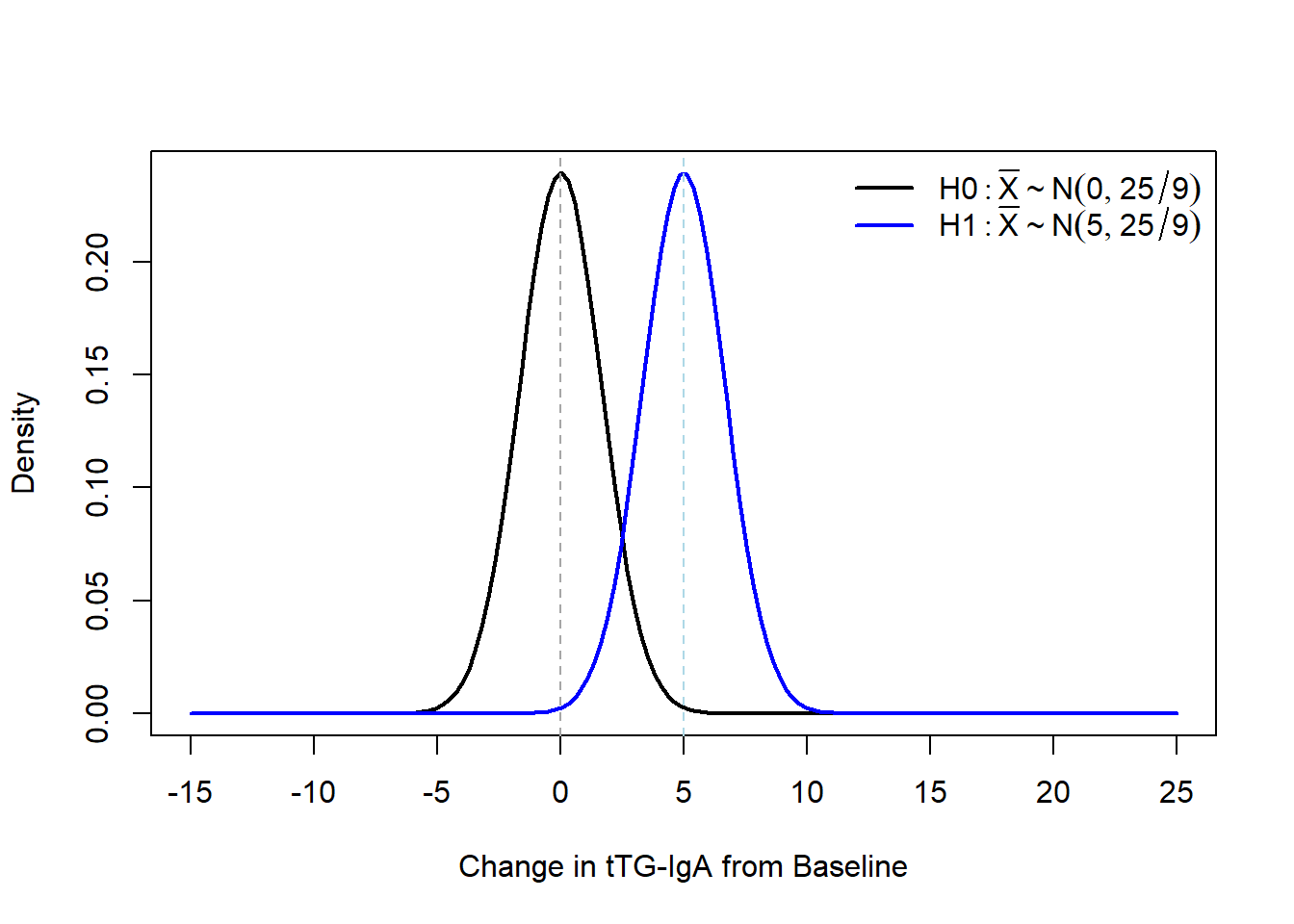
Under \(H_0\) we know that we would need to enroll 9 participants to achieve at least 83% power. We can calculate what this corresponds to by doing some algebra with our standard normal \(Z\): \[ Z_{0.975} = 1.96 = \frac{\bar{x}-\mu}{\sigma / \sqrt{n}} = \frac{\bar{x}-0}{5 /\sqrt{9}} \implies \bar{x} = 1.96 \frac{5}{\sqrt{9}} \approx 3.27 \]
If we didn’t want to have the time of our lives doing algebra, we could also leverage the qnorm() function by specifying our given mean and SD:
qnorm(0.975, mean=0, sd=sqrt(25/9))[1] 3.266607If we add that information to our figure, we can see that the area under our curve for \(H_1\) is at least 83%:
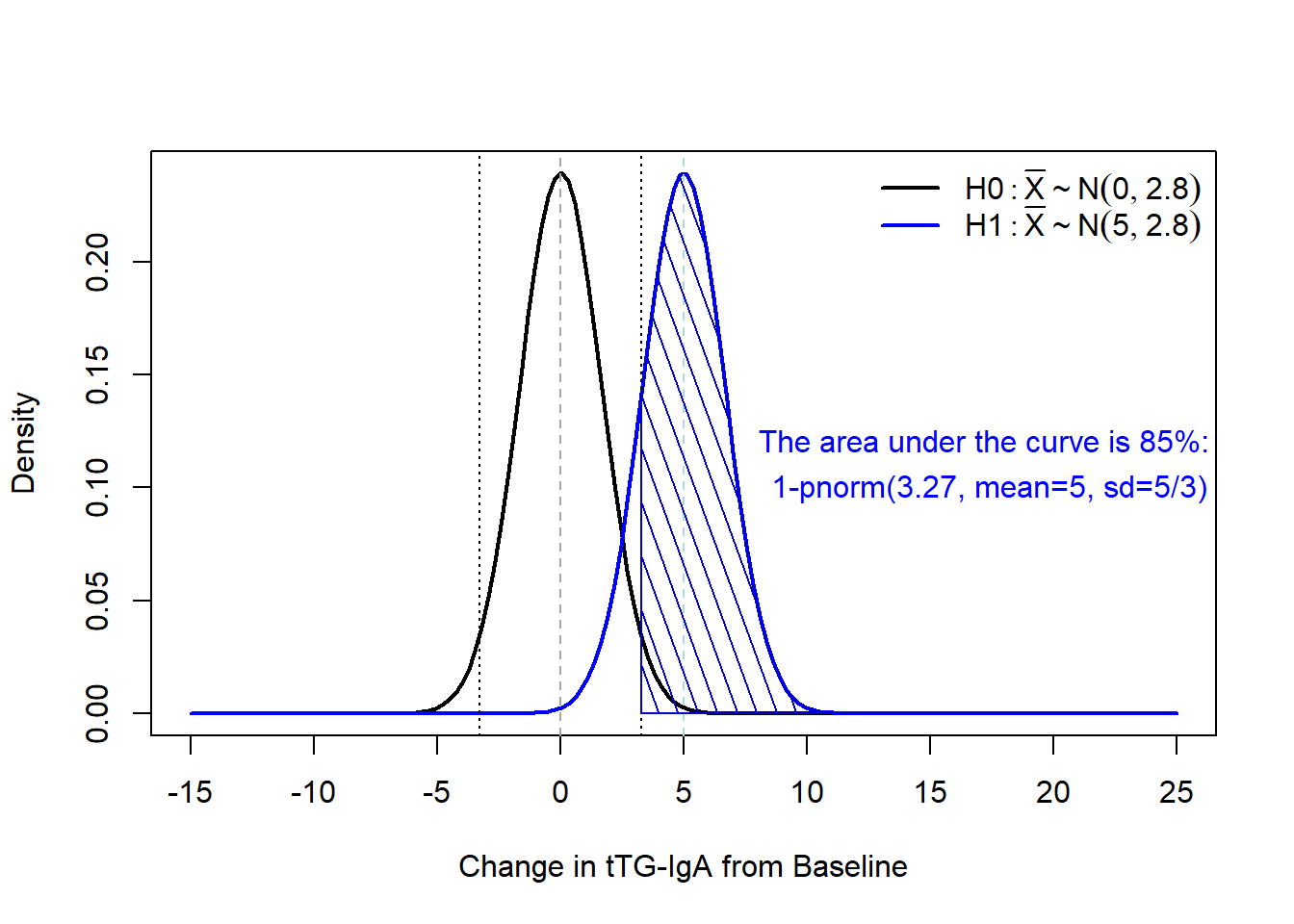
As we noted on the plot, we achieve 85% power with \(n=9\), \(\sigma=5\), \(\alpha=0.05\), and a detectable difference of 5:
1 - pnorm(3.27, mean=5, sd=5/3) # upper AUC for H1[1] 0.850365pnorm(3.27, mean=5, sd=5/3, lower.tail=F) # upper AUC for H1 specified with lower.tail argument[1] 0.850365If we wanted to be more precise with our impractical \(n=8.4681\), we can see we do achieve exactly 83% power:
specific_n <- (qnorm(0.83)+qnorm(0.975))^2 # from our "by hand" formula
1 - pnorm(qnorm(0.975, mean=0, sd=sqrt(25/specific_n)), mean=5, sd=5/sqrt(specific_n) )[1] 0.83We can also use the nifty NHST visualization by Kristoffer Magnusson: https://rpsychologist.com/d3/nhst/. The big difference with the visualization tool is that Cohen’s \(d\) is used instead of specifying the mean and standard deviation separately:
\[ d = \frac{\mu - \mu_0}{\sigma} = \frac{5 - 0}{5} = 1 \]
We can confirm our power is 85% in the visualization by setting \(d=1\) and our other parameters.
Next, let’s see what happens for the unknown SD case:
power.t.test(n=NULL, delta=5, sd=5, sig.level=0.05, power=0.83, type='one.sample')
One-sample t test power calculation
n = 10.57855
delta = 5
sd = 5
sig.level = 0.05
power = 0.83
alternative = two.sidedWhen we treat the SD as unknown we now need to enroll 11 participants.
Let’s break down a bit more about why the normal distribution and t-distribution end up with different estimates. When we assume the SD is unknown we now have to estimate it from the data we collect. In the context of our power calculations, it reflects a greater level of uncertainty as to what we are planning for. We can visually see this uncertainty by adding the t-distribution to our \(H_0\) figure:
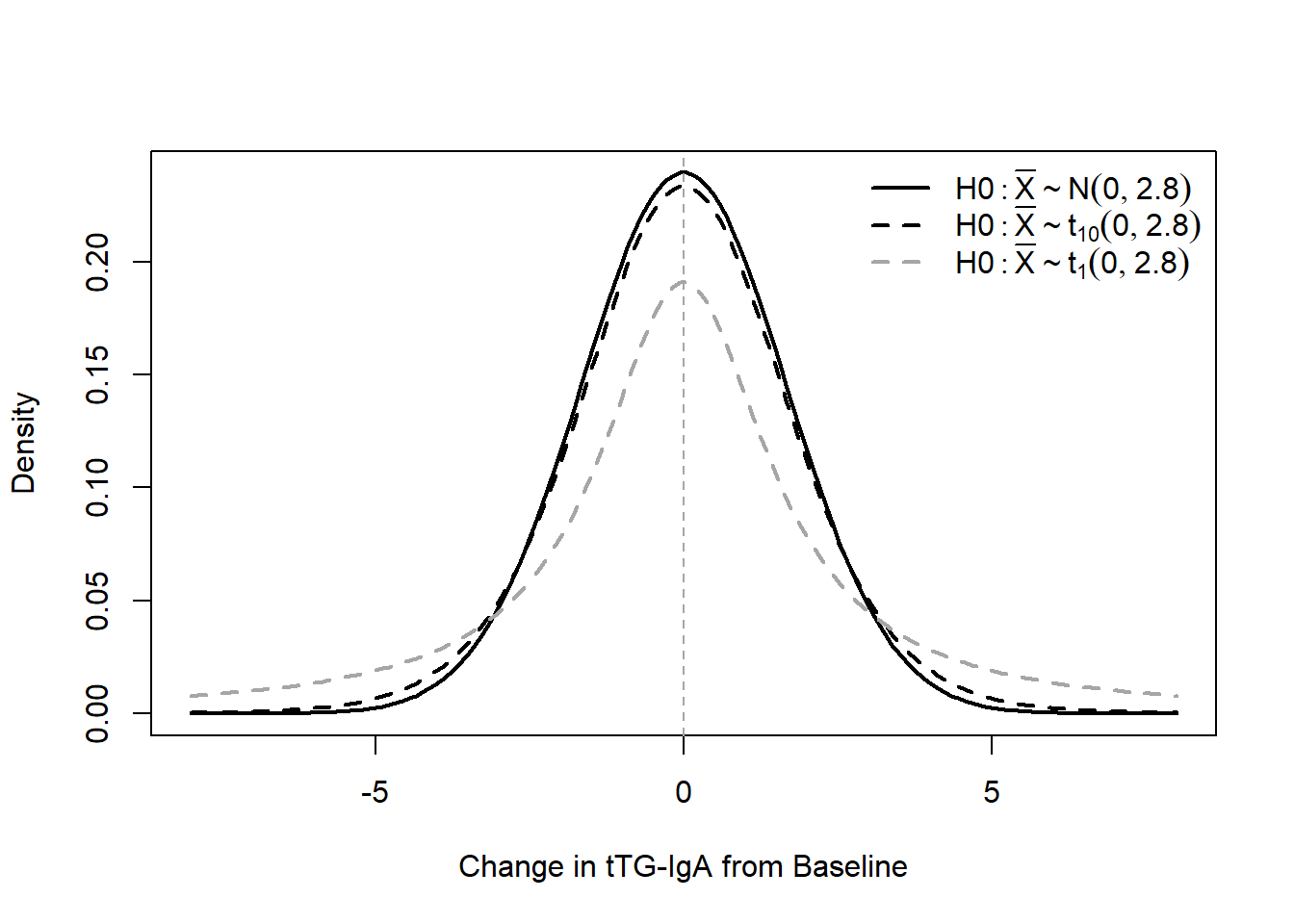
We can see that as the degrees of freedom increase, the t-distribution gets closer in shape to our normal distribution. This apparent change is notable especially when comparing \(df=1\) to \(df=10\), where smaller degrees of freedom lead to the t-distribution decreasing the peak and increasing the fattiness of the tails. This will have a direct effect if we didn’t change any of our calculations relative to the standard normal distribution.
For example, if we look at the overlap of our two t-distributions under \(H_0\) and \(H_1\) while keeping the known SD critical values from above with our \(n=11\) from the power calculation (where \(\frac{s}{\sqrt{n}}=\frac{5}{\sqrt{11}}=1.51\)):
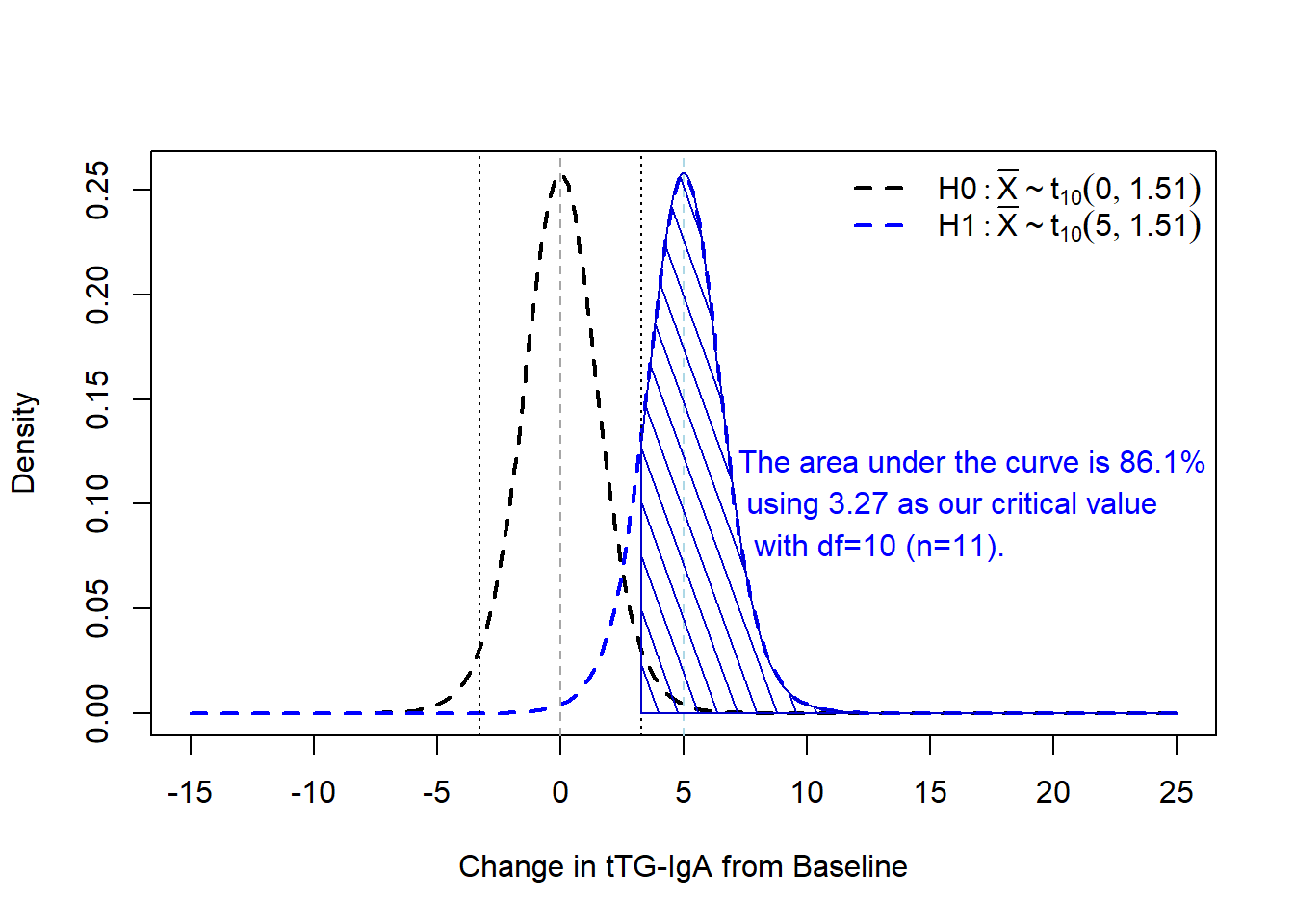
We can calculate this via the metRology package’s pt.scaled function:
library(metRology)
1 - pt.scaled(3.27, df=10, mean=5, sd=5/sqrt(11))[1] 0.8610669In actuality, since are assuming an unknown SD, we should recalculate the critical value appropriate for this context. Doing so below, with the qt.scaled() function, and applying it to our estimate of power is a little closer to the targeted 83% power:
qt.scaled(0.975, df=11-1, mean=0, sd=5/sqrt(11)) # calculate the critical value based on our unknown SD[1] 3.3590461 - pt.scaled(3.36, df=11-1, mean=5, sd=5/sqrt(11)) # calculate power under critical value[1] 0.8489082More precisely, enrolling \(n=10.57855\) achieves approximately 83% power:
n <- 10.57855 # use n from power.t.test above
crit_tdist_n <- qt.scaled(0.975, df=n-1, mean=0, sd=5/sqrt(n)) # calculate the critical value based on our unknown SD
crit_tdist_n # critical value to compare to 3.36 above[1] 3.4458441 - pt.scaled(crit_tdist_n, df=n-1, mean=5, sd=5/sqrt(n)) # calculate power under critical value[1] 0.8315566Again, however, in practice we round up to \(n=11\) to ensure at least 83% power is achieved (and because we are unable to enroll fractions of an event or participant).